







Smart bins, also known as smart waste management systems, are an innovative solution to traditional waste collection methods. By integrating advanced technologies such as machine learning, smart bins have become a reliable and efficient way of predicting waste levels and improving the waste management process.
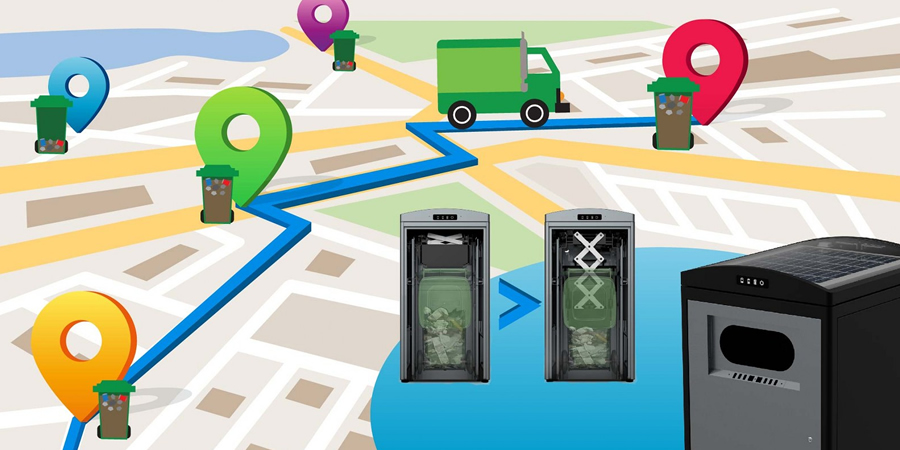
Machine learning algorithms can be used to predict waste levels in smart bins by analyzing data from sensors and cameras installed in the bins. The data includes the weight and volume of waste, type of waste, and the time it was disposed. The algorithms can use this data to create models that accurately predict the waste level in the bin and determine when the bin is likely to reach its maximum capacity.
Smart bins equipped with machine learning algorithms can help optimize waste collection routes and reduce the frequency of waste collection. By predicting waste levels, waste collection companies can prioritize the bins that need to be emptied first, reducing the number of empty bins on the street and improving the efficiency of waste collection.
Smart bins with machine learning algorithms can also help reduce waste and improve sustainability. By predicting waste levels, smart bins can encourage people to reduce waste and recycle more by providing feedback on the amount of waste they generate. Moreover, smart bins can be programmed to separate waste into recyclables, compostables, and landfill, helping to increase the recycling rate and reduce the amount of waste sent to landfills.
Smart bin prediction systems using machine learning can also provide valuable data for city planners and waste management companies. By analyzing data from smart bins, waste management companies can gain a better understanding of waste generation patterns, the types of waste generated in different areas, and the times when waste is generated. This information can help city planners make informed decisions about waste management infrastructure, such as the placement of bins and the frequency of collection.
In conclusion, smart bin prediction systems using machine learning are a crucial tool in improving waste management and reducing waste. With their ability to predict waste levels, optimize waste collection routes, reduce waste and increase sustainability, smart bins are helping to create a greener and cleaner future.
Machine learning algorithms can be used to predict waste levels in smart bins by analyzing data from sensors and cameras installed in the bins. The data includes the weight and volume of waste, type of waste, and the time it was disposed. The algorithms can use this data to create models that accurately predict the waste level in the bin and determine when the bin is likely to reach its maximum capacity.
Smart bins equipped with machine learning algorithms can help optimize waste collection routes and reduce the frequency of waste collection. By predicting waste levels, waste collection companies can prioritize the bins that need to be emptied first, reducing the number of empty bins on the street and improving the efficiency of waste collection.
Smart bins with machine learning algorithms can also help reduce waste and improve sustainability. By predicting waste levels, smart bins can encourage people to reduce waste and recycle more by providing feedback on the amount of waste they generate. Moreover, smart bins can be programmed to separate waste into recyclables, compostables, and landfill, helping to increase the recycling rate and reduce the amount of waste sent to landfills.
Smart bin prediction systems using machine learning can also provide valuable data for city planners and waste management companies. By analyzing data from smart bins, waste management companies can gain a better understanding of waste generation patterns, the types of waste generated in different areas, and the times when waste is generated. This information can help city planners make informed decisions about waste management infrastructure, such as the placement of bins and the frequency of collection.
In conclusion, smart bin prediction systems using machine learning are a crucial tool in improving waste management and reducing waste. With their ability to predict waste levels, optimize waste collection routes, reduce waste and increase sustainability, smart bins are helping to create a greener and cleaner future.




